Cluster Quality Measures Sklearn
The SSE is defined as the sum of the squared distance between each member of the cluster and its centroid. For the class the labels over the training data can be.
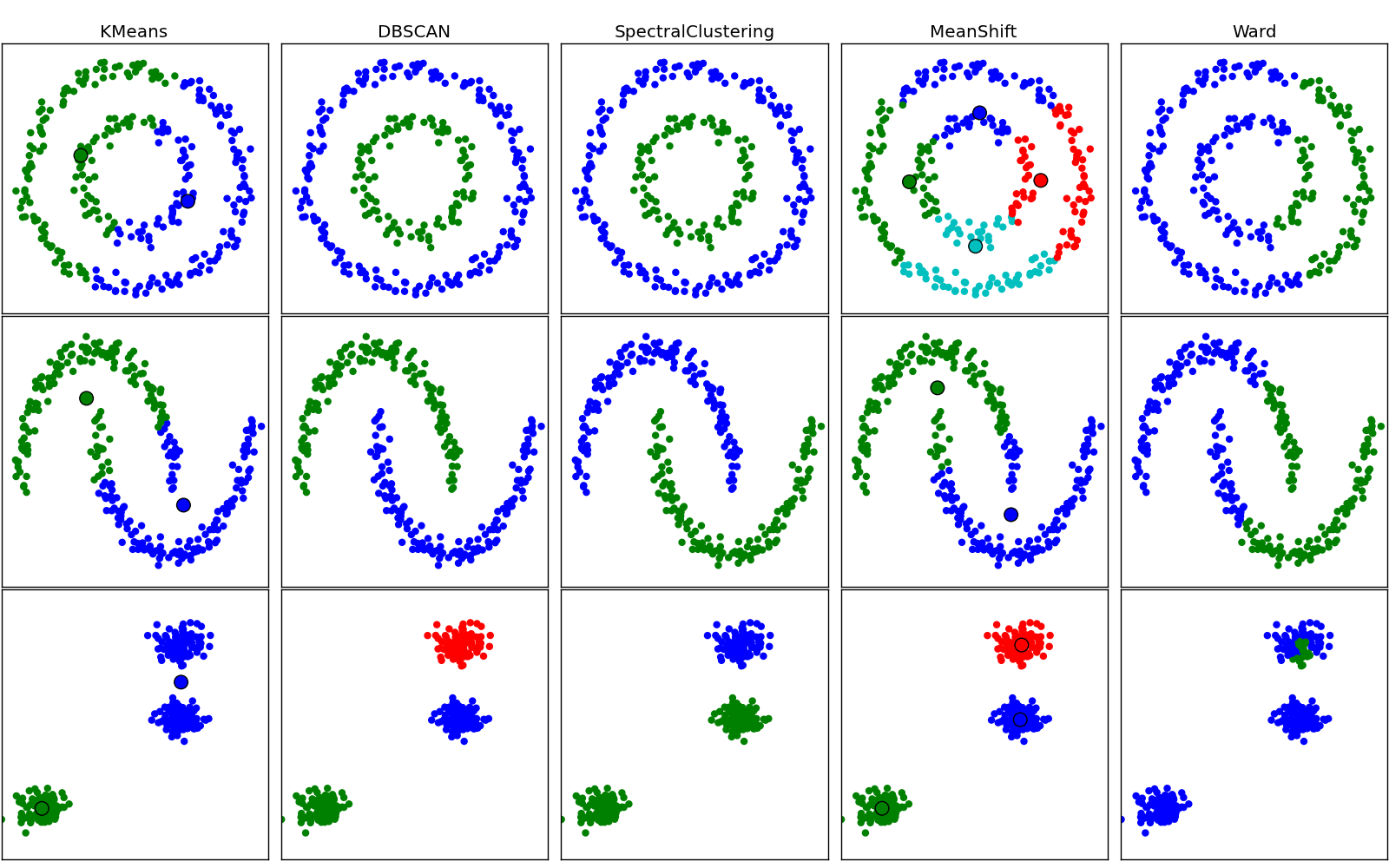
4 3 Clustering Scikit Learn 0 11 Git Documentation
Where i j and k are each indices for clusters d measures the inter-cluster distance and d measures the intra-cluster difference.
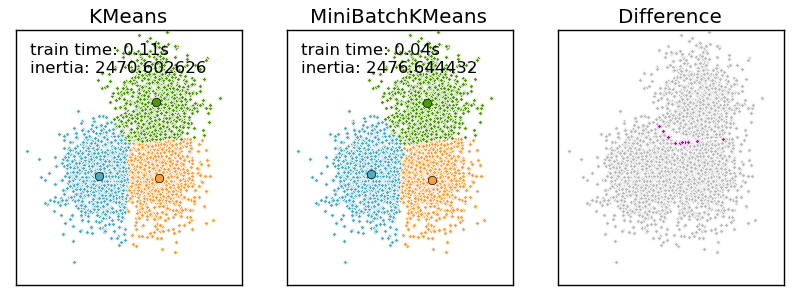
Cluster quality measures sklearn. There are two forms of evaluation. Silhouette analysis can be used to study the separation distance between the resulting clusters. Letting G V E be an undirected graph with adjacency matrix A we use three of the standard cluster quality metrics in our study.
For clustering we have to find the best match between the class labels and the cluster labels so accuracy is defined by. Clustering of unlabeled data can be performed with the module sklearncluster. Silhouette analysis can be used to study the separation distance between the resulting clusters.
Homogeneity metric of a cluster labeling given a ground truth. K where K is the number of clusters. Cluster labels to evaluate.
The idea of the Elbow Criterion method is to choose the kno of cluster at which the SSE decreases abruptly. Ratio of weight attributed to homogeneity vs completeness. Here TP True Positive number of pair of points belonging to the same clusters in true as well as predicted labels both.
The silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters and thus provides a way to assess parameters like number of clusters visually. A c c u r a c y y y max p e r m P 1 n i 0 n 1 1 p e r m y i y i where P is the set of all permutations in 1. There are a variety of different metrics that attempt to evaluate the quality of a clustering by capturing the notion of intra-cluster density and inter-cluster sparsity.
The Silhouette Score and Silhouette Plot are used to measure the separation distance between clusters. 10 stands for perfectly complete labeling. This measure has a range of -1 1.
The formula for the Dunn Index is as follows. The clustering score would be SaAbB - cC or even SaA bB cC. Each clustering algorithm comes in two variants.
There are many clustering algorithms to choose from and no single best clustering algorithm for all cases. This metric is independent of the absolute values of the labels. If beta is greater than 1 completeness is weighted more strongly in the calculation.
Overview One of the fundamental characteristics of a clustering algorithm is that its for the most part an unsurpervised learning process. The Adjusted Rand Index is a variation on the classic Rand Index and attempts to express what proportion of the cluster assignments are correct. This measure has a range of -1 1.
Score between 00 and 10. A class that implements the fit method to learn the clusters on train data and a function that given train data returns an array of integer labels corresponding to the different clusters. Calculate Sum of Squared ErrorSSE for each value of k where k is no.
A permutation of the. Lets consider some metrics to actually help us assign a number to our cluster quality. There are two forms of evaluation.
Supervised which uses a ground truth class values for each sample. The silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters and thus provides a way to assess parameters like number of clusters visually. It displays a measure of how close each point in a cluster is to points in the neighbouring clusters.
It is often used as a data analysis technique for discovering interesting patterns in data such as groups of customers based on their behavior. The Fowlkes-Mallows function measures the similarity of two clustering of a set of points. Whereas traditional prediction and classification problems have a whole host of accuracy measures RMSE Entropy PrecisionRecall etc it might seem a little more abstract coming up with a comparable measure of goodness of fit for the way an.
A clustering result satisfies homogeneity if all of its clusters contain only data points which are members of a single class. How does Sklearn measure clustering performance. SSE tends to decrease toward 0 as we increase k SSE0 when k is equal to.
This measure has a range of -1 1 and is a great tool to visually inspect the similarities within clusters and differences across clusters. Of cluster and plot the line graph. It computes a similarity measure between two different clusterings by considering all pairs of samples and counting pairs that are.
It may be defined as the geometric mean of the pairwise precision and recall. In this example with compare the various initialization strategies for K-means in terms of runtime and quality of the results. Where a b and c are weighting coefficients related to situations.
The sklearnmetricscluster submodule contains evaluation metrics for cluster analysis results. Modularity conductance and coverage. Instead it is a good idea to explore a range of clustering.
As the ground truth is known here we also apply different cluster quality metrics to judge the goodness of fit of the cluster labels to the ground truth. Sklearnmetricshomogeneity_scorelabels_true labels_pred source. The Dunn Index.
Clustering or cluster analysis is an unsupervised learning problem. Say you have qualities A B and a dis-quality C. If beta is less than 1 homogeneity is weighted more strongly.
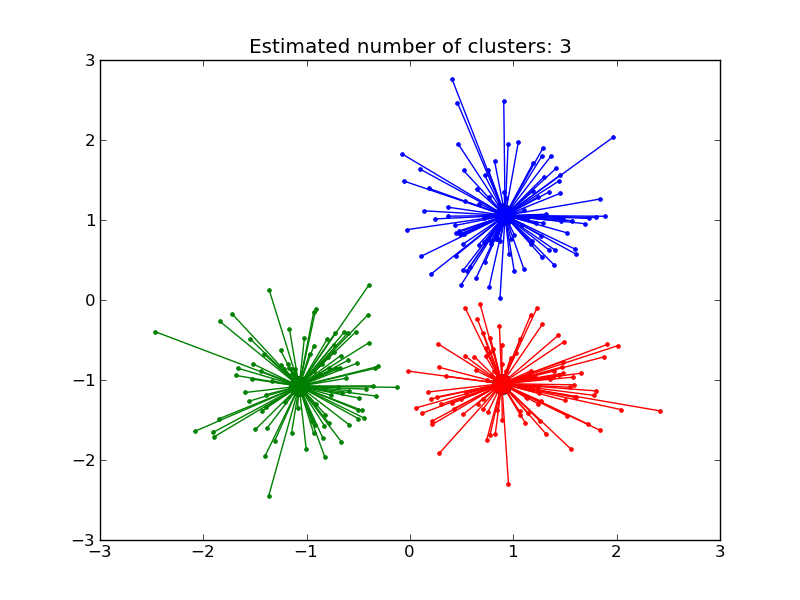
4 3 Clustering Scikit Learn 0 11 Git Documentation

Scikit Learn Unsupervised Learning Clustering
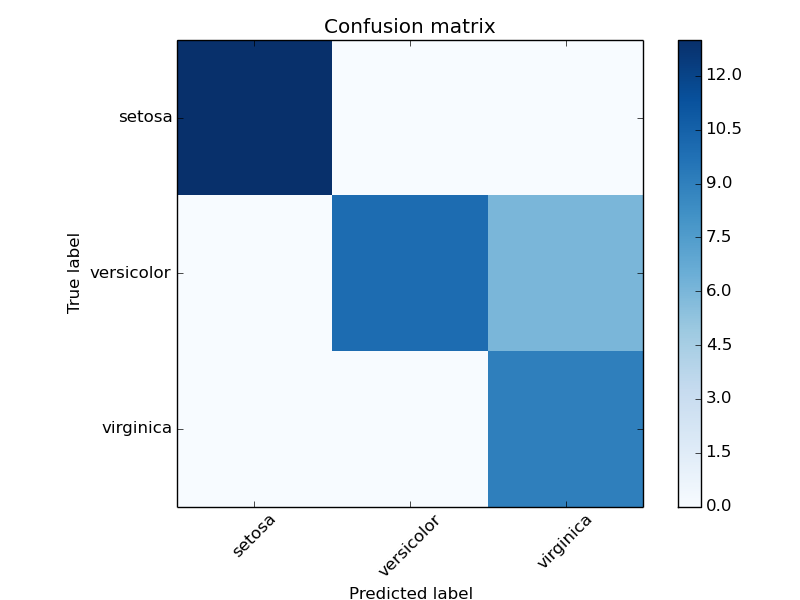
3 3 Model Evaluation Quantifying The Quality Of Predictions Scikit Learn 0 16 1 Documentation
{kind=link}
Posting Komentar untuk "Cluster Quality Measures Sklearn"