Cluster Example In Data Mining
In many applications clustering analysis is widely used such as data analysis market research pattern recognition and image processing. Applications of Cluster Analysis in Data Mining.
Clustering Types Of Clustering Clustering Applications
How Businesses Can Use Data Clustering Clustering can help businesses to manage their data better image segmentation grouping web pages market segmentation and information retrieval are four examples.
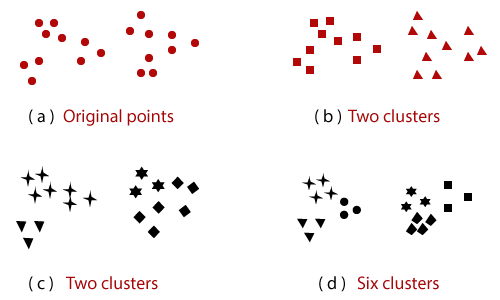
Cluster example in data mining. Using Euclidean distance 3 Move each cluster center to the mean of its assigned items 4 Repeat steps 23 until convergence change in cluster assignments less than a threshold. For each data point within a given cluster the radius of a given cluster has to contain at least number of points. In this model the number of clusters required at the end is known in prior.
The Learning phase is carried out using the maximum likelihood. Using the techniques of Data Mining and Business Intelligence allows these service providers to predict when a customer leaves them for another service provider which in terms is known as churn. With the help of Clustering the dealerseller can find or determine a set of groups in their customer base.
A group of data points would comprise together to form a cluster in which all the objects would belong to the same group. A data mining clustering algorithm assigns data points to different groups some that are similar and others that are dissimilar. Click on Next.
It assists marketers to find different groups in their client base and based on the purchasing patterns. θML argmax θ P x1xnθ The purpose is to find a parameter θ that maximized the probability of the observed data. Partitioning Method K-Mean in Data Mining.
For example if we perform K- means clustering we all know its O n where n is that the number of objects within the data. This clustering method classifies the information into multiple groups based on the characteristics and similarity of the data. We usually see Cluster analysis being used in general in many applications.
This often leaves only the following 3. Data mining K means algorithm is the best example that falls under this category. The following are some points why clustering is important in data mining.
We will use the make_classification function to create a test binary classification dataset. This includes the R system and the Weka open-source Java library. Various techniques such as regression analysis association and clustering classification and outlier analysis are applied to data to identify useful outcomes.
On the Select Data Source View page choose Tips from the Available data. On the Create the Data Mining Structure page press the radio button labeled Create mining structure with a mining model. In the average-link clustering is to find the average distance between any data point of one cluster to any data member of the other cluster.
Data Mining which is also known as Knowledge Discovery in Databases KDD is a process of discovering patterns in a large set of data and data warehouses. This Data Mining Clustering method is based on the notion of density. The clusters are visually obvious in two dimensions so that we can plot the data with a scatter plot and color the points in the plot by the assigned cluster.
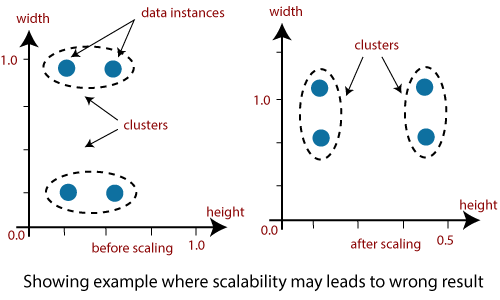
Scalability in clustering implies that as we boost the amount of data objects the time to perform clustering should approximately scale to the complexity order of the algorithm. Parallel Data Mining Many mature and feature-rich data mining libraries and products are available. Its the data analysts to specify the number of clusters that has to be generated for the clustering methods.
Basic version works with numeric data only 1 Pick a number K of cluster centers - centroids at random 2 Assign every item to its nearest cluster center eg. Some of the examples of Data Mining in Day to day life are - 1 - Service Providers. We require highly scalable clustering algorithms to work with large databases.
Unfortunately most data mining solutions are not designed for execution in large distributed systems. The idea is to continue growing the given cluster. P y1ynx1xn θ P x1xn y1ynθ joint P x1xnθ marginal probability Learning.
It can be classified based on the following categories. Data Mining Centroid Models. Data Mining Cluster Analysis.
The dataset will have 1000 examples with two input features and one cluster per class. Marketers can find a specific group of customers and they can categorize those groups of customers according to. They have been using Data Mining to retain customers for a very long time.
Algorithms should be able to work with the type of data such as categorical numerical and binary data. That is exceeding as long as the density in the neighbourhood threshold. Cluster Analysis in Data Mining Cluster analysis is very popular in applications such as data analysis image processing pattern recognition market.
Choose the Microsoft Clustering data mining technique from the drop-down box. Cluster Analysis is the process to find similar groups of objects in order to form clustersIt is an unsupervised machine learning-based algorithm that acts on unlabelled data. For example if we perform K- means clustering we know it is O n where n is the number of objects in the data.
Applications of cluster analysis in data mining. For example market research pattern recognition data analysis image processing and so on. In the partitioning method when database D that contains.
Scalability in clustering implies that as we boost the amount of data objects the time to perform clustering should approximately scale to the complexity order of the algorithm. They can characterize their customer groups.
Clustering In Machine Learning Algorithms That Every Data Scientist Uses Dataflair
Data Mining Cluster Analysis Javatpoint

Difference Between Classification And Clustering In Data Mining Stack Overflow
{kind=link}
Posting Komentar untuk "Cluster Example In Data Mining"